OLS (Ordinary Least Squares) Regression
Can we explain variation in a defendant’s risk score
(risk_score) from the combination of their
number of prior misdemeanors (priors) and
their age (age)?
Here, we’ll be working from the Defendants2025 data set to
examine the impact of a defendants number of prior misdemeanors
(priors: as an interval-ratio variable) and
their risk score (risk_score: as an
interval-ratio variable), while also accounting for the defendant’s age
(age: as an interval-ratio variable).
What is the Regression?
The OLS regression examines the predictive relationship between some independent variable(s), and an interval-ratio dependent variable. The test tells us about the effect (slope) of any independent (X) variable on an interval-ratio dependent (Y) variable. In particular, the regression equation looks at how values of an x variable “predict” a specific Y value.
To do this, we use regression (AKA: linear regression, multiple
regression, multivariate regression, multivariable regression, ordinary
least squares regression) on the Defendants2025 data set,
with risk score (risk_score) as the DV, number of prior
misdemeanors (priors) as IV1, and age (age) as
IV2.
Assumptions and Diagnostics for Regression
The assumptions for the regression are…
- Adequate Sample Size
- Absence of Outliers
- Absence of Multicollinearity and Singluarity
- Linearity, Normality, and Homoscedasticity (Homogeneity of Variance)
In addition, the previously-discussed assumptions for other tests (independence of observations) is implied, since all of these bivariate tests require random samples. Beyond this, the OLS regression requires an interval-ratio outcome variable.
1. Adequate Sample Size
- According to Green (1991), as cited in Tabachnick and Fidel (2006), adequate sample size is determined by the modified equation \(N \geq 50 + 8(k)\)
Where \(k\) is the number of independent variables included in the regression model.
- Given that we have two IVs/predictor
variables, the minimum number of cases to be adequate is 66 (\(66 = 50 + 8(2)\)). With only \(n = 1738\) observations in the
Defendants2025data set, we have more than enough cases to adequately run the regression model. That is,we have met the assumption of adequate sample size.
2. Absence of Outliers
To identify outliers, simply look at the boxplots for each interval-ratio variable in the model (Y and all interval-ratio Xs) to see how outlying, these outliers are. In most cases, outliers should remain in the data, and you need strong justification for removing outlying cases.
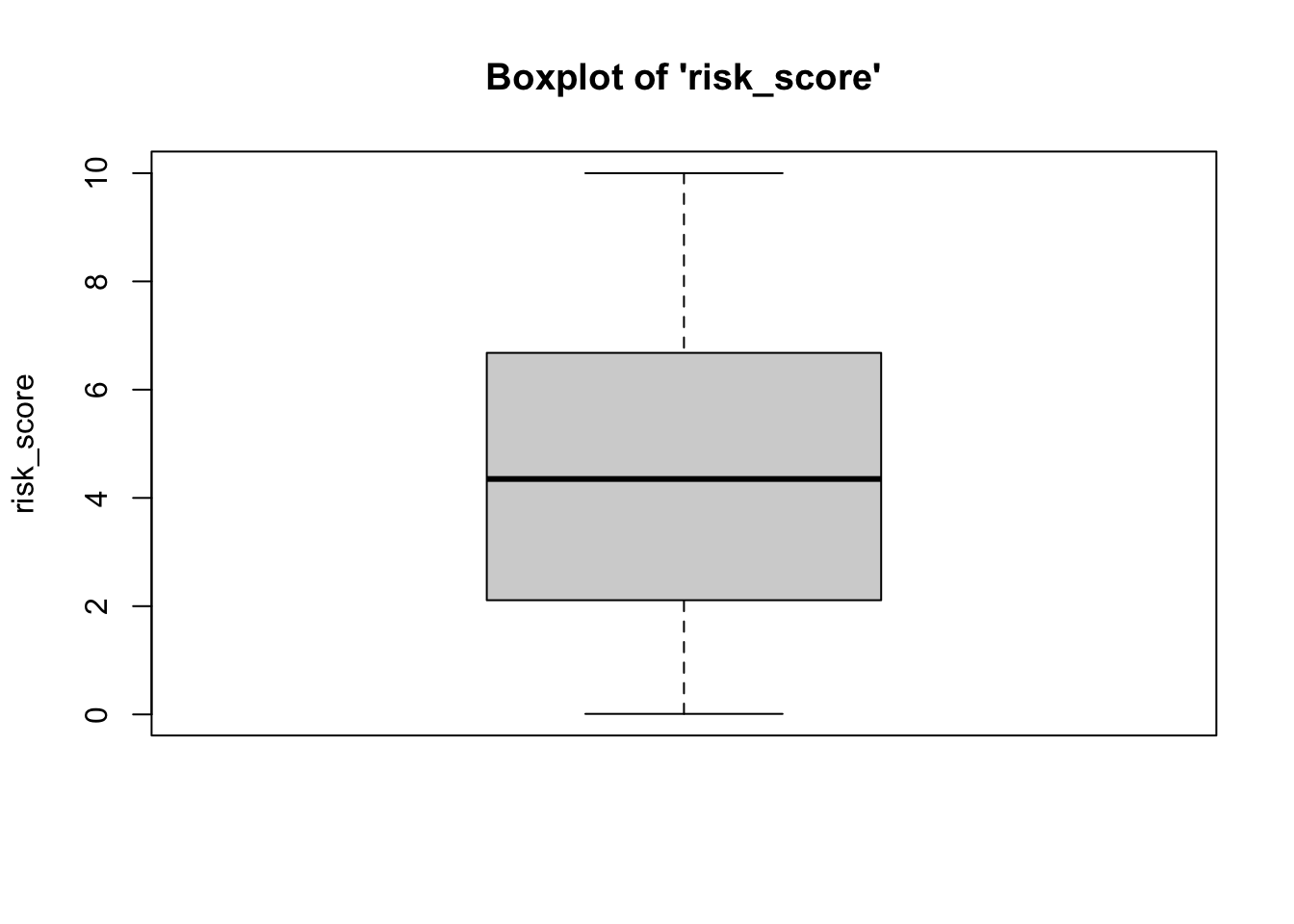
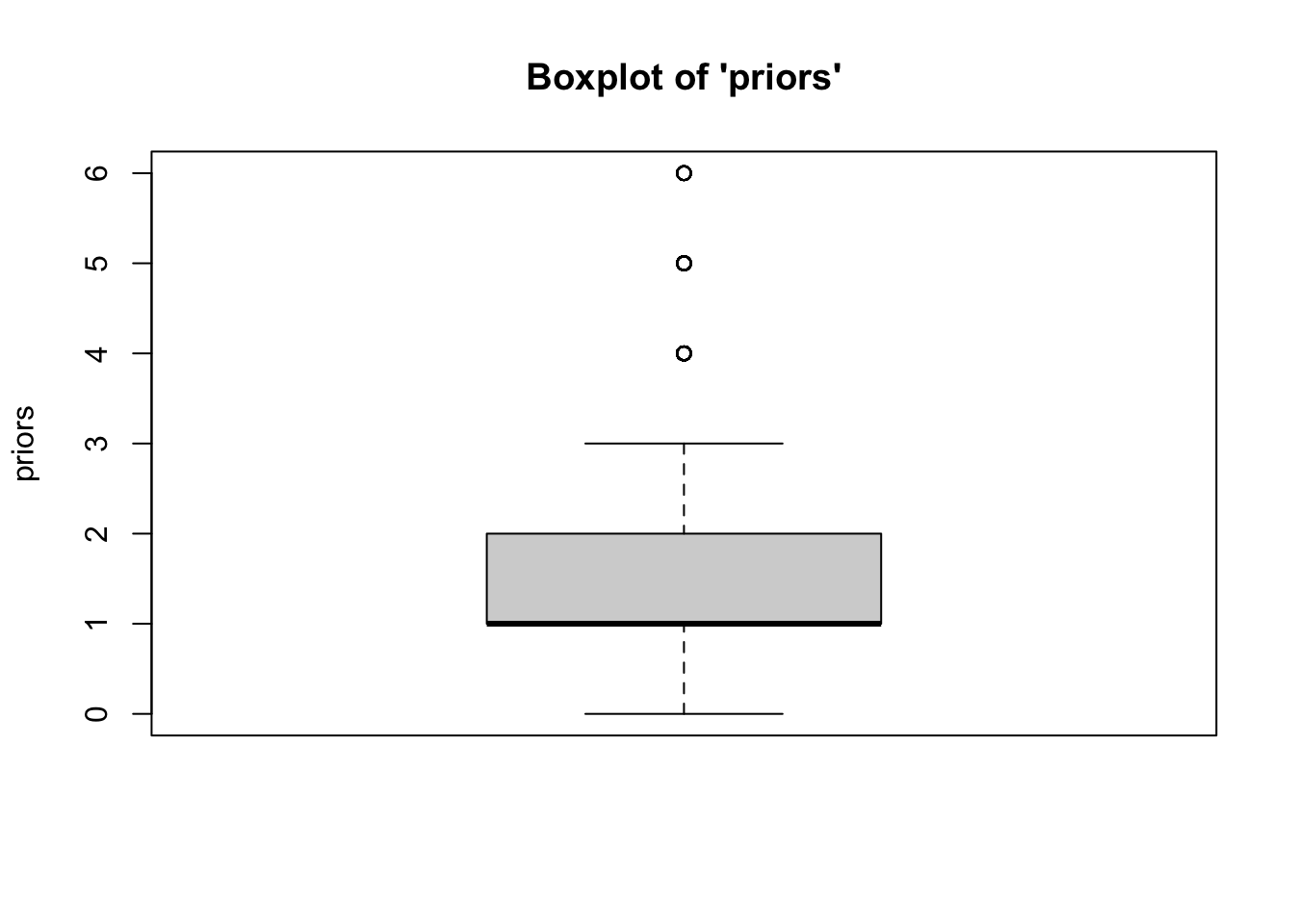
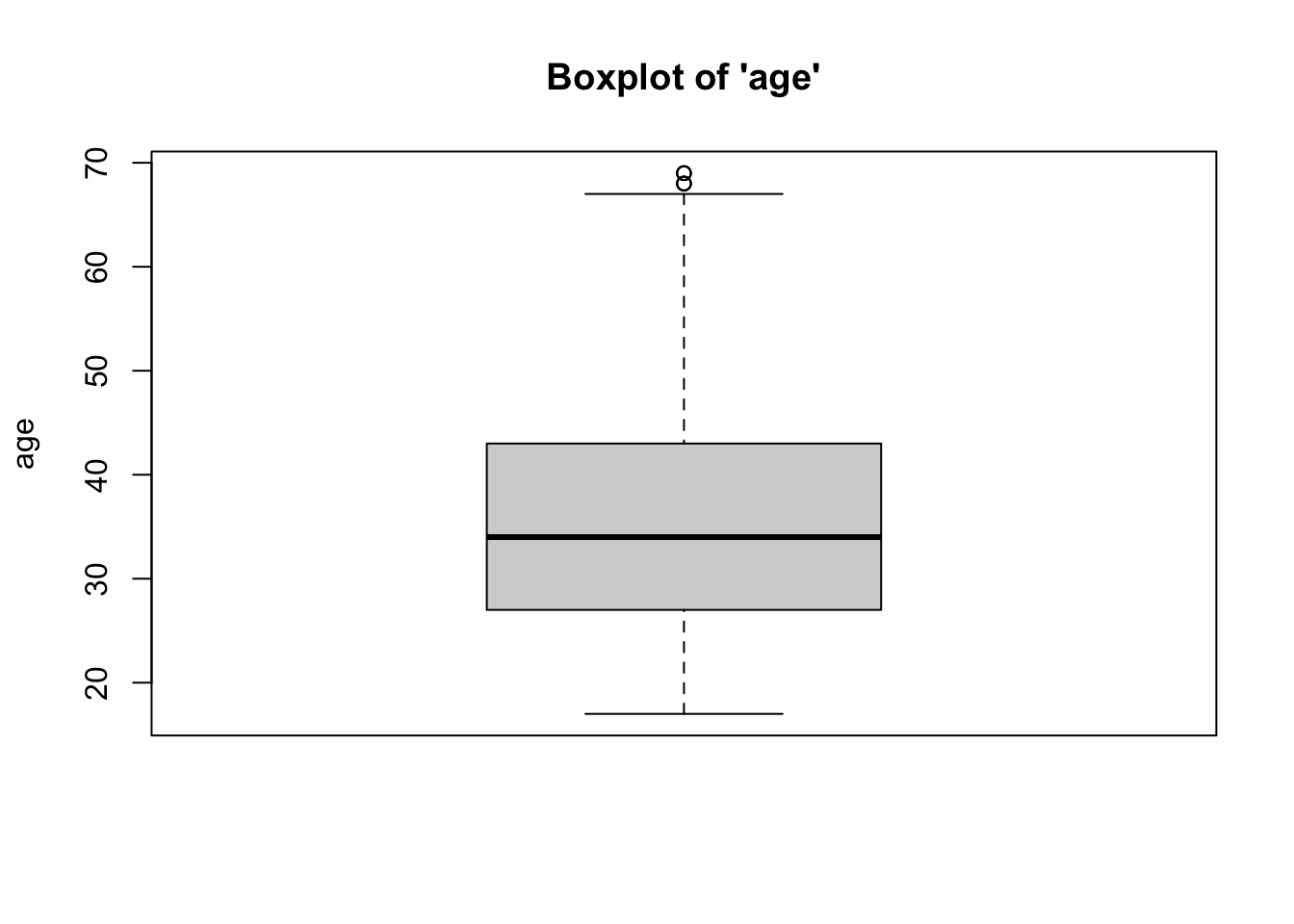
- We can see from the boxplots that the
distributions of the variables are relatively normal. The boxplot for
risk_scoreis particularly normal. The boxplots forpriorsandagehave some issues: Forpriors, the median falls at the 25th percentile, and the upper whisker (right tail) of the distribution has some outliers, implying a longer right tail. Similarly, foragethere are a couple of outliers at higher ages, implying a longer right tail. While we might consider removing these outlying cases, we would need to do so statistically (beyond the scope of this class). Taken together, however,these data represent a relative absence of outliers.
3. Multicollinearity and Singularity
Multicollinearity: Independent variables (more) highly correlated with one another (compared to their correlation with the DV).
- Check the correlation matrix for variables.
## risk_score priors age
## risk_score 1
## priors 0.15 1
## age -0.37 -0.02 1- We can see from the correlation matrix that
none of the bivariate relationships between the independent variables
(
priorsandage) are above a correlation coefficient of \(r \approx .90\). Therefore,we have met the assumption of absence of multicollinearity.
Singularity: If independent variables included are (together) all possible subsets of measure also included in model. For example, if you have a xenophobia scale… based on 4 different questions (the sum of the scale is a “total xenophobia” scale)… and you include all 4 questions in the regression model, AND you include the total scale (the sum of the 4 questions) in the model. There will be so much overlap in the total scale, and the 4 items, that all of them would appear in the regression model with no coefficients… no \(b\) values…
- Look at the items and determine if they are subsets of other items also included.
- Based on the data,
priorsandageare not subsets of one another. Therefore,we have met the assumption of absence of singularity.
4. Linearity, Normality, and Homoskedasticity
- Linearity: Variables move together in a linear fashion.
- Normality: Variables are normally-distributed.
- Homoskedasticity: Homogeneity of Variance - Variance of variables
are similar (10:1, 3:1 for SDs).
- Visual inspection of Residuals Plot to see if relationship is linear, normal, and similar variances. Plot should have points that extend beyond both sides of the 0 line (normality), should not have a U or inverted-U shape in the points (linearity), and it should not have a funnel shape, where points are tightly clustered near the 0 line at one end of the plot, and completely dispersed along y-axis at other end of plot (homoskedasticity).
In the past, you may have been instructed to use the Shapiro-Wilk test to assess normality. This is wrong. Unfortunately, tests such as these are overly-sensitive to trivial deviations from normality, and may result in you believing you must correct for normality by transforming your data. Please do not do this. OLS regression is robust enough to provide results even in the presence of data that are not fully normally-distributed. You may have also been instructed to use the Levene’s test to assess the degree of similarity in variances across groups. Similarly, this test is overly-sensitive to trivial deviations from homogeneity of variance. It is a better practice to assess all three (linearity, normality, and homoskedasticity) using a Residuals Plot.
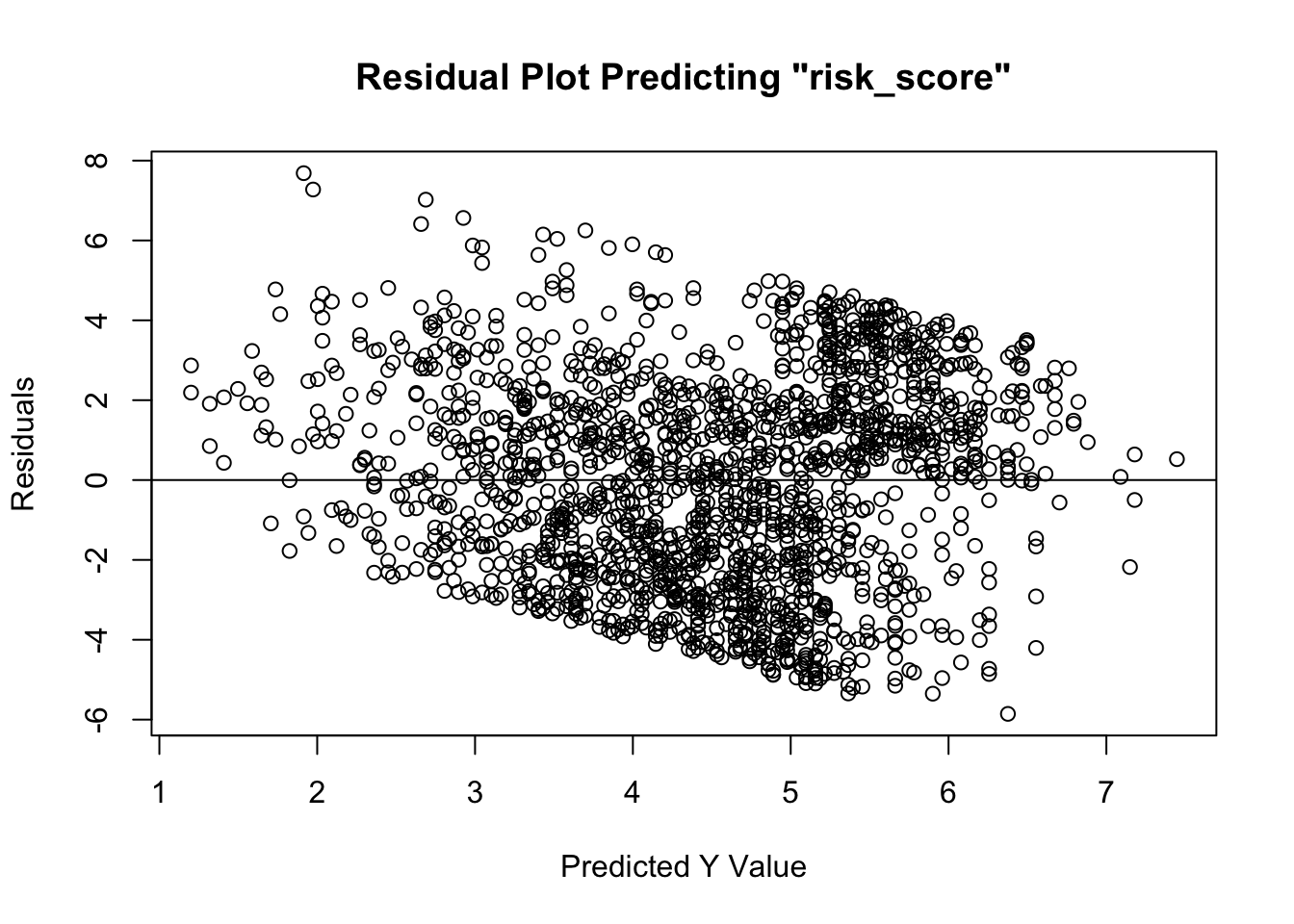
- Based on the residuals plot (the difference
between the actual \(Y\) and the \(\hat{Y}\)), we see that
we have met the assumptions of linearity, normality, and homoskedasticity. Linearity is met given that the residuals do NOT exhibit a non-linear/curvilinear relationship about the 0 distance (from \(\hat{Y}\)) line. Normality is met given that the residuals do not have a hard stop on either side of the line – that is, they are evenly distributed about the 0 distance (from \(\hat{Y}\)) line. Finally, homoskedasticity is met given that the residuals are evenly distanced from the 0 distance (from \(\hat{Y}\)) line at all values of \(\hat{Y}\) – as exemplified the lack of “fanning out” on one end (although we see a slight negative trend in the data)
The Regression Calculation
The calculation for the Regression is:
\(\hat{Y} = b_0 + b_1X_1 + b_2X_2\)
Where…
- \(\hat{Y}\) is the predicted Y value for the combination of slopes for X values
- \(b_0\) is the intercept
- \(b_1\) is the slope associated with \(X_1\)
- \(b_2\) is the slope associated with \(X_2\)
- \(X_1\) is a specific value for the first \(X\) variable that you can plug in for a specific case
- \(X_2\) is a specific value for the second \(X\) variable that you can plug in for a specific case
Running the Regression
For Regression, within the lm function, which stands for
linear model, the dependent variable is listed first and the
independent variable is listed second.
This may seem confusing, so it’s best to wrap our lm function in a summary call…
##
## Call:
## lm(formula = risk_score ~ priors + age, data = data1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.856 -2.094 0.197 1.922 7.686
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.178966 0.216408 33.173 < 2e-16 ***
## priors 0.297496 0.046601 6.384 2.21e-10 ***
## age -0.089231 0.005412 -16.487 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.562 on 1735 degrees of freedom
## Multiple R-squared: 0.1545, Adjusted R-squared: 0.1535
## F-statistic: 158.5 on 2 and 1735 DF, p-value: < 2.2e-16To interpret the findings, we report the following information:
The test used
The variables used in the full model
For significant variables, how a variable’s slope affects the outcome
The amount of variance in the outcome explained by the combination of IVs.
- In the output above, using an OLS
regression, we see the Y-intercept (or mean risk score) is
7.179. In addition, we see that the \(b\) for the priors variable is significant
and positively related to risk score, such that, for every 1-unit
(however it is measured) increase in the number of prior misdemeanors a
defendant has, there is a .297-unit increase in their
risk score. Additionally, age is significant and negatively related to
risk score, such that, for every 1-unit increase in a defendant’s age
(e.g. year), there is a .089-unit decrease in their
risk score.
We also see that this model is significantly better than the null model (with no predictors), as indicated by the omnibus F test: \(F(2,1735) = 158.5, p\lt.05\).
Finally, for this full model, which explains/predicts a defendant’s risk score from their number of priors and their age, the model fit statistic, the \(R^2\), is .1545. This indicates that 15.45 percent of the variation in a defendant’s risk score (risk_score) is explained by the combination of their number of prior misdemeanors (priors) and their age (age).
- In the output above, using an OLS
regression, we see the Y-intercept (or mean risk score) is
7.179. In addition, we see that the \(b\) for the priors variable is significant
and positively related to risk score, such that, for every 1-unit
(however it is measured) increase in the number of prior misdemeanors a
defendant has, there is a .297-unit increase in their
risk score. Additionally, age is significant and negatively related to
risk score, such that, for every 1-unit increase in a defendant’s age
(e.g. year), there is a .089-unit decrease in their
risk score.