Correlation (Pearson’s Product Moment Correlation Coefficient)
Is there a relationship between a defendant’s age
(age) their risk score
(risk_score)?
Here, we’ll be working from the Defendants2025 data set, to
examine the relationship between a defendant’s age
(age: measured in years) and their risk score
(risk_score).
What is the correlation?
The correlation (\(r\)) or Pearson’s product-moment correlation coefficient examines the association or relationship between two interval-ratio variables to see if the relationship reflects a true relationship that we could expect to find in the population. The test also tells us the strength (weak, moderate, strong) and direction (positive, negative) of that relationship. Rarely, we will see a non-relationship or a perfect relationship.
Assumptions and Diagnostics for Correlation
The assumptions for the Correlation are…
- Linearity
- Normality
In addition, the previously-discussed assumptions for other tests (independence of observations) is implied, since all of these bivariate tests require random samples.
1. Linearity
- Variables move together in a linear fashion. Visual inspection of
scatterplot to see if relationship is linear
(straight-line). You can call a scatterplot using the
scatterfunction in thevannstatspackage:
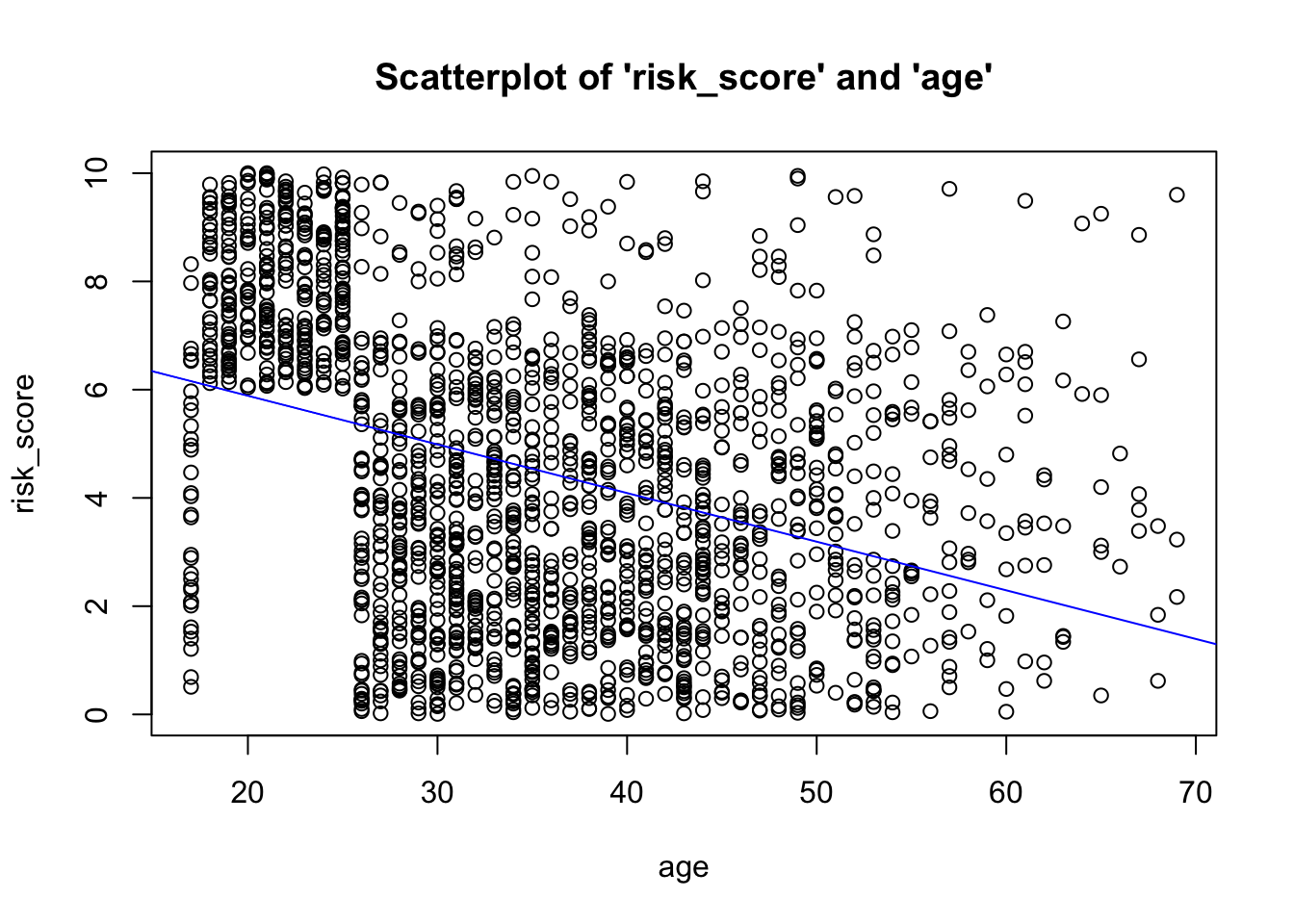
- Given that we don’t see a non-linear
(e.g. curvilinear) relationship, and that the points generally cluster
near the “line of best fit” (AKA the regression line),
we have met the assumption of linearity.
2. Normality
- Distributions must be relatively normal. Unlike the t-test and
ANOVA, where you look at clustered plots (histograms, boxplots, and Q-Q
plots), displaying the means, broken out by levels/categories of the
grouping variable for correlation, you must visually inspect the
same plots for each variable.
- Inspect individual plots for each variable…
- Histograms
- Box-and-Whiskers plot
- Normality (Q-Q) plot
- Inspect individual plots for each variable…
In the past, you may have been instructed to use the Shapiro-Wilk test to assess normality. This is wrong. Unfortunately, tests such as these are overly-sensitive to trivial deviations from normality, and may result in you believing you must correct for normality by transforming your data. Please do not do this. The correlation is robust enough to provide results even in the presence of data that are not fully normally-distributed.
2a. Histogram
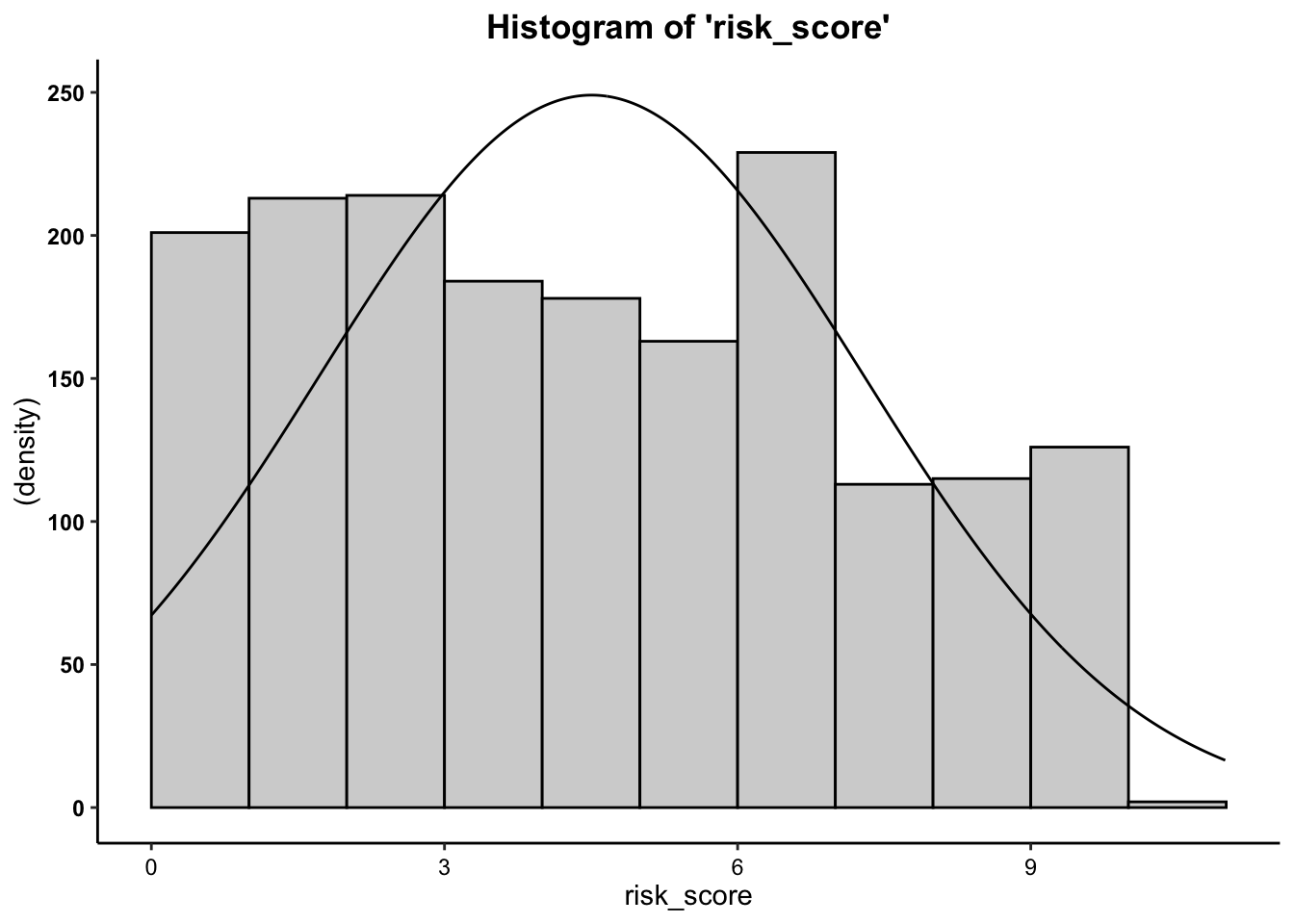
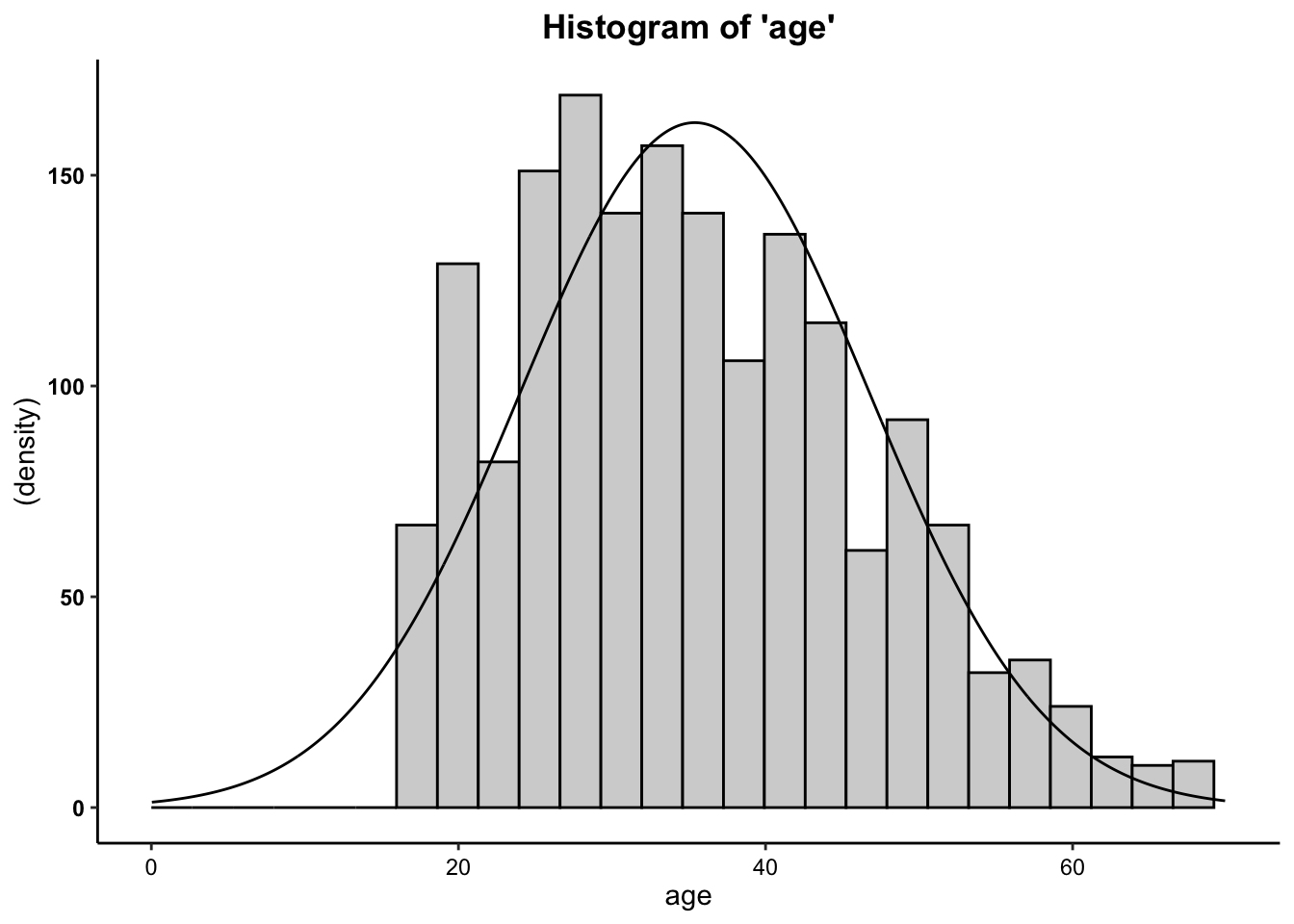
- We can see from the histograms that the
distributions of both variables are relatively normal. Overall, these
data are close enough to normal.
2b. Box-and-Whisker Plots
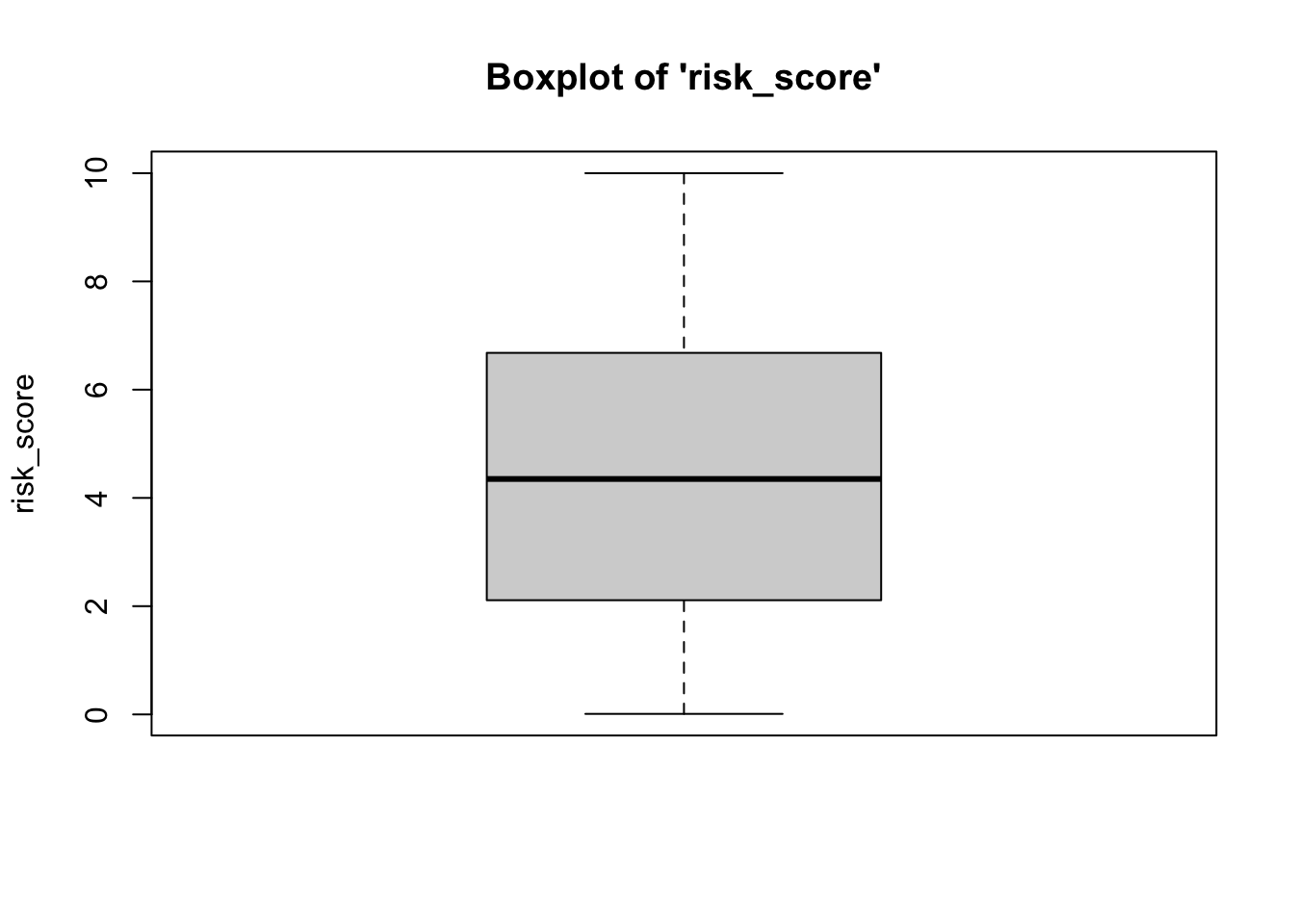
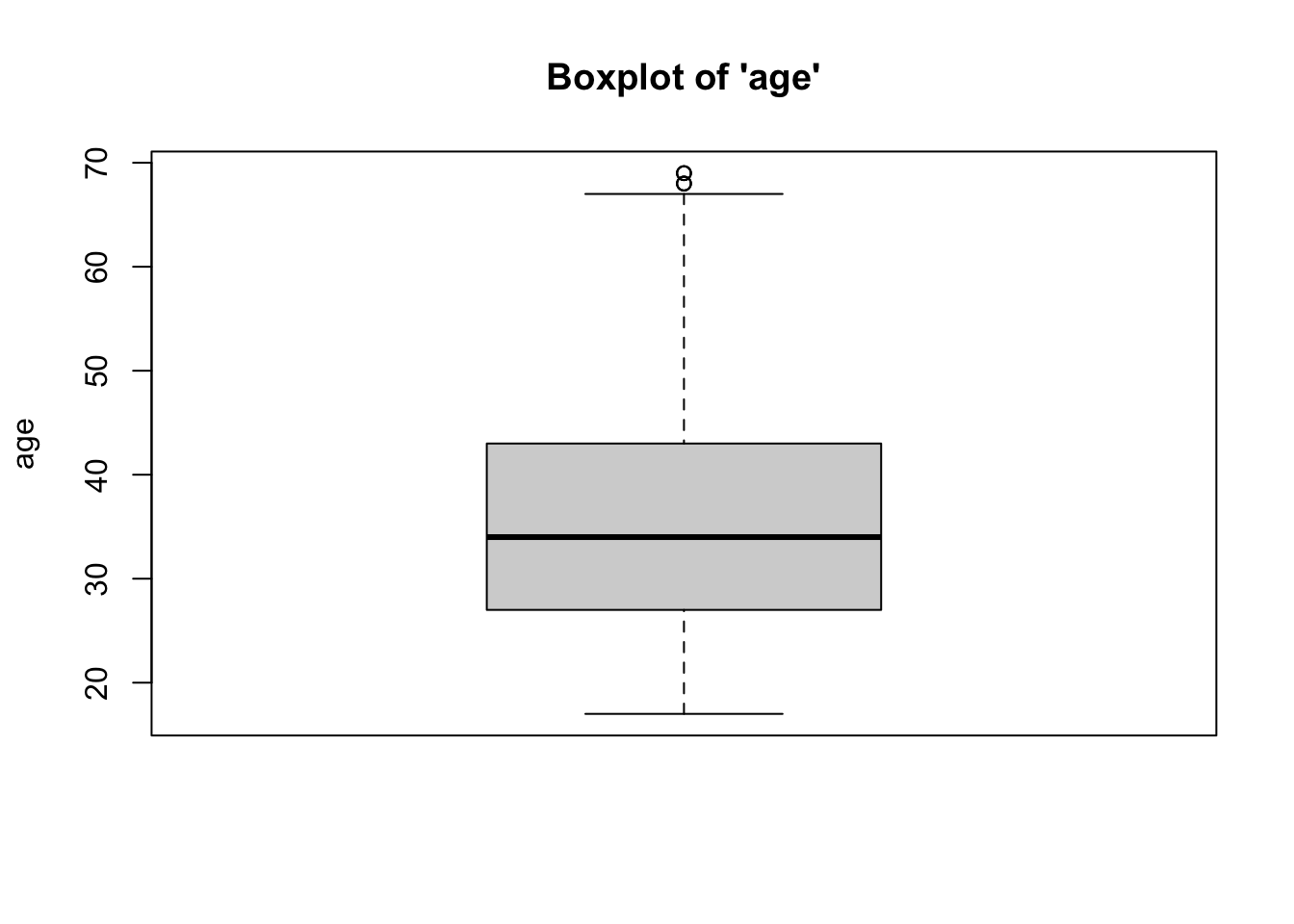
- We can see from the boxplots that the distributions of both variables are relatively normal. Interestingly, the boxplot for the age variable has some issues: the upper whisker (right tail) of the distribution for age variable has some outliers, implying a longer right tail. While we might consider removing these outlying cases, we would need to do so statistically (considering how outlying an outlier is)… which is beyond the scope of this class. Overall, however, these data are close enough to normal.
2c. Normality (Q-Q) Plots
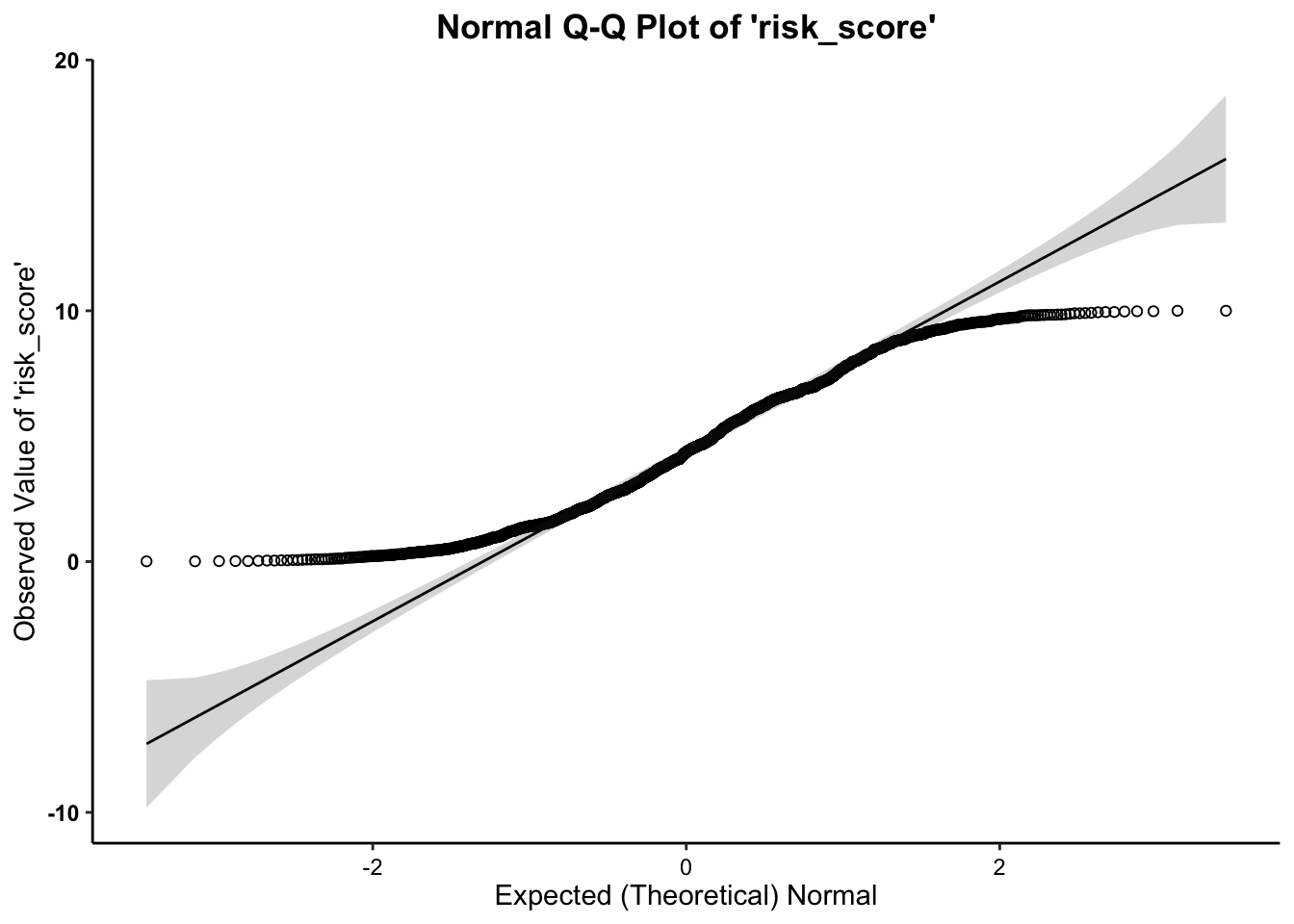
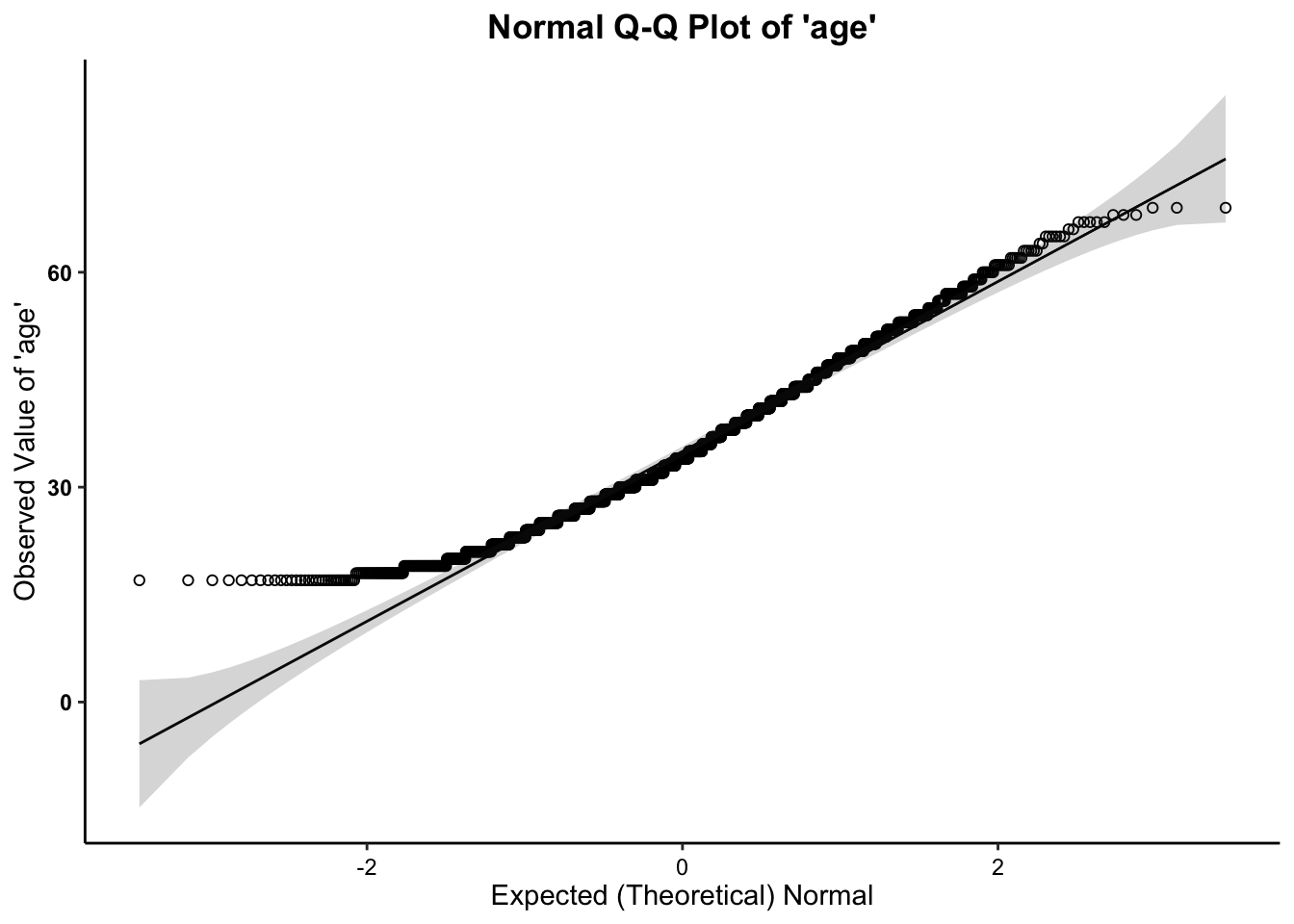
- We can see from the Q-Q plots that the distributions of both variables are relatively normal, with the exception of the tails. The tails of both age and risk score have observed data points that are higher (on the low end) and lower (on the high end) than would be expected if the data followed a normal distribution. We might consider removing outliers, but doing so would alter the expected normal distribution/curve for the rest of the data, and is not suggested.
- Across all three plots of
risk_scoreand all three plots ofage, the variables do not seem to drastically deviate from normality. Therefore,we can assume normality.
The Correlation Test Calculation
The calculation for the correlation is:
\(r = \frac{\sum (X - \bar{X})(Y - \bar{Y})}{\sqrt{\sum (X - \bar{X})^2 \sum(Y - \bar{Y})^2}}\)
In addition, the degrees of freedom (\(df\)) for the test is…
* \(df = N - 2\)
Running the Correlation
For Correlation, within the p.corr function, the dependent
variable is listed first and the independent variable is listed
second.
##
## Pearson's product-moment correlation
##
## data: risk_score and age
## 𝒓 = -0.36687, df = 1736, p-value < 2.2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.4068727 -0.3254666
## sample estimates:
## 𝒕
## -16.43158In the output above, we see the \(r\)-obtained value (-0.36687), the degrees of freedom (1736), and the p-value (2.2 x \(10^{-16}\) = .00000000000000022), which is much less than our set alpha level of .05).
To interpret the findings, we report the following information:
- The test used
- If you reject or fail to reject the null hypothesis
- The variables used in the analysis
- The degrees of freedom, calculated value of the test (\(r_{obtained}\)), and \(p-value\)
- \(r(df) = r_{obtained}\), \(p-value\)
“Using the Pearson’s correlation test (\(r\)), I reject/fail to reject the null hypothesis that there is no association between variable one and variable 2, in the population, \(r(?) = ?, p ? .05\)”
- “Using the Pearson’s correlation test (\(r\)), I reject the null hypothesis that there is no relationship between a defendant’s age and their risk score, in the population, \(r(1736) = -0.36687, p \lt .05\). In particular, we have a moderate negative relationship between age and risk score, such that, as age increases, their risk score decreases.”