Chi-Square Example
Is there an association between political orientation and views of the Black Lives Matter movement?
The Chi Square Test of Independence
The Chi Square test (\(X^2\)) examines the association or relationship between two nominal/ordinal variables to see if the relationship reflects a true relationship that we could expect to find in the population. The test also tells us whether or not a category (attribute) of one variable varies by categories of another variable.
For this example, the Chi Square test works perfectly because we’re looking at categories of the political orientation variable (liberal and conservative) across categories of another (positive and negative views of the Black Lives Matter movement) to see if there is a true association between political orientation and views of BLM in the population.
Reading in the Data
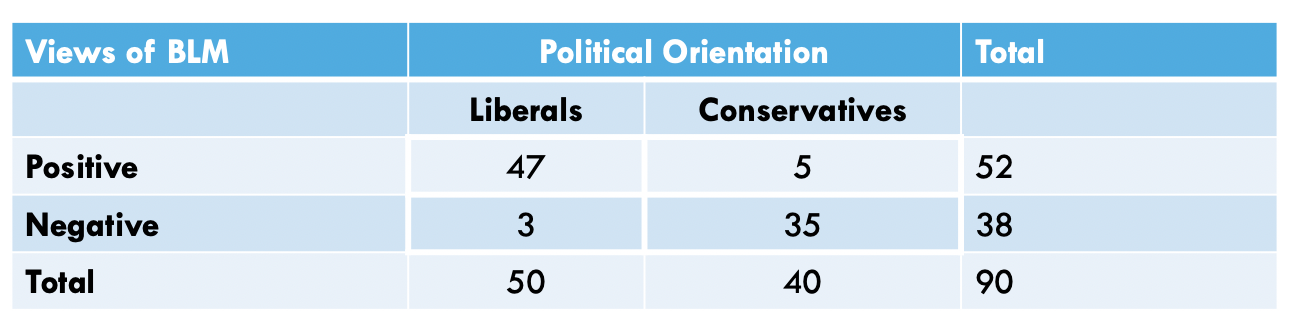
In the table (above), we have a total of 90 people, randomly-sampled.
We see (by looking at the column marginals) that we have a total of 50
liberal individuals and 40 conservatives in the sample. By looking
closer at the cells, we see that, of the 50 liberals, 47 have positive
views of BLM while the other 3 have negative views of BLM. Moreover, of
the 40 conservatives, 5 have positive views of BLM while the other 35
have negative views of BLM. We can use this breakdown to create a data
set, using a combination of the concatenate, c(), data frame data.frame, and the repeat rep() functions.
The repeat function comes in handy when you have to type out the same
values over and over again. This function has two arguments: 1) the
thing you want to repeat, and 2) the number of times you want to repeat
it. For example, let’s say I wanted to create an object called x, that repeats the number 7, 10 times. I would do the
following:
and the data would look like this…
## [1] 7 7 7 7 7 7 7 7 7 7Next, let’s say I wanted to create an object called y, that repeats the string, word,
or, in more appropriate terms, group/category student, 25 times. I would do the
following:
and the data would look like this…
## [1] "student" "student" "student" "student" "student" "student" "student"
## [8] "student" "student" "student" "student" "student" "student" "student"
## [15] "student" "student" "student" "student" "student" "student" "student"
## [22] "student" "student" "student" "student"Using this logic, we can apply the repeat function to create each variable, concatenating across the various categories of each variable, and combine these variables into a data frame… as such…
pol <- c(
rep("liberal",50),
rep("conservative",40)
)
views <- c(
rep("positive",47),
rep("negative",3),
rep("positive",5),
rep("negative",35)
)For brevity, I don’t call the variables here, but instead, I’ll merge the variables into one data frame, using the following:
and the data should look like this, in your Environment window…
Assumptions and Diagnostics for Chi Square
The assumptions for the Chi Square are…
- Independence of Observations
- Normality
1. Independence of Observations (Examine Data Collection Strategy)
- Cases (observations) are not related or dependent upon each other.
Case can’t have more than one attribute. No ties between observations.
Examine data collection strategy to see if there are linkages between
observations.
- These data were randomly sampled.
Therefore, we meet the assumption of independence of observations.
- These data were randomly sampled.
2. Normality (Examine Crosstabs for Expected Frequencies)
- Distributions must be relatively normal.The normality assumption is met if no more than 20 percent of the cells in our Expected Frequencies Crosstab have fewer than 5 cases. Therefore, if (\(E \lt 5\)) for more than 20 percent of the cells in the Expected Frequences table, the assumption of normality is violated.
To check if you’ve met the assumption of normality (e.g. fewer than 20% of cells in the crosstab of expected frequencies falls below \(n=5\)), you use the following:
## $`Observed Frequencies`
## pol: conservative liberal Total
## views: negative 35 3 38
## positive 5 47 52
## Total 40 50 90
##
## $`Expected Frequencies`
## pol: conservative liberal Total
## views: negative 16.88889 21.11111 38
## positive 23.11111 28.88889 52
## Total 40.00000 50.00000 90- We see here that less than 20% of cells in
the 2x2 table have fewer than 5 expected counts (actually, no cell has
fewer than 5).
Therefore, we meet the assumption of normality.
The Chi Square Test Calculation
The calculation for the Chi Square is:
\(X^2 = \sum \frac{(f_o - f_e)^2}{f_e}\) or \(X^2 = \sum \frac{(f_{o_i} - f_{e_i})^2}{f_{e_i}}\)
where…
- \(f_o\) (or \(f_{o_i}\)) is the observed frequency for
that cell (the \(i^{th}\)cell)
- \(f_e\) (or \(f_{e_i}\)) is the expected frequency for
that cell (the \(i^{th}\)cell)
- \(f_e\) (or \(f_{e_i}\)) for each cell is calculated by
the following:
- \(f_e\) (or \(f_{e_i}\)) \(= \frac{(r_{total_i})(c_{total_i})}{total}\) \(= \frac{(n_{row_i})(n_{column_i})}{N}\)
- \(f_e\) (or \(f_{e_i}\)) for each cell is calculated by
the following:
In addition, the degrees of freedom (\(df\)) for the test is…
* \(df = (r-1)(c-1)\)
where…
- \(r\) is the number of rows in a
crosstabulation
- \(c\) is the number of columns in a
crosstabulation
Running the Chi Square Test
For Chi Square, within the chi.sq function, the dependent
variable is listed first and the independent variable is listed
second.
#chisq.test(data$views, data$pol, correct=FALSE)
chi <- chi.sq(data, views, pol, post = T, plot = T)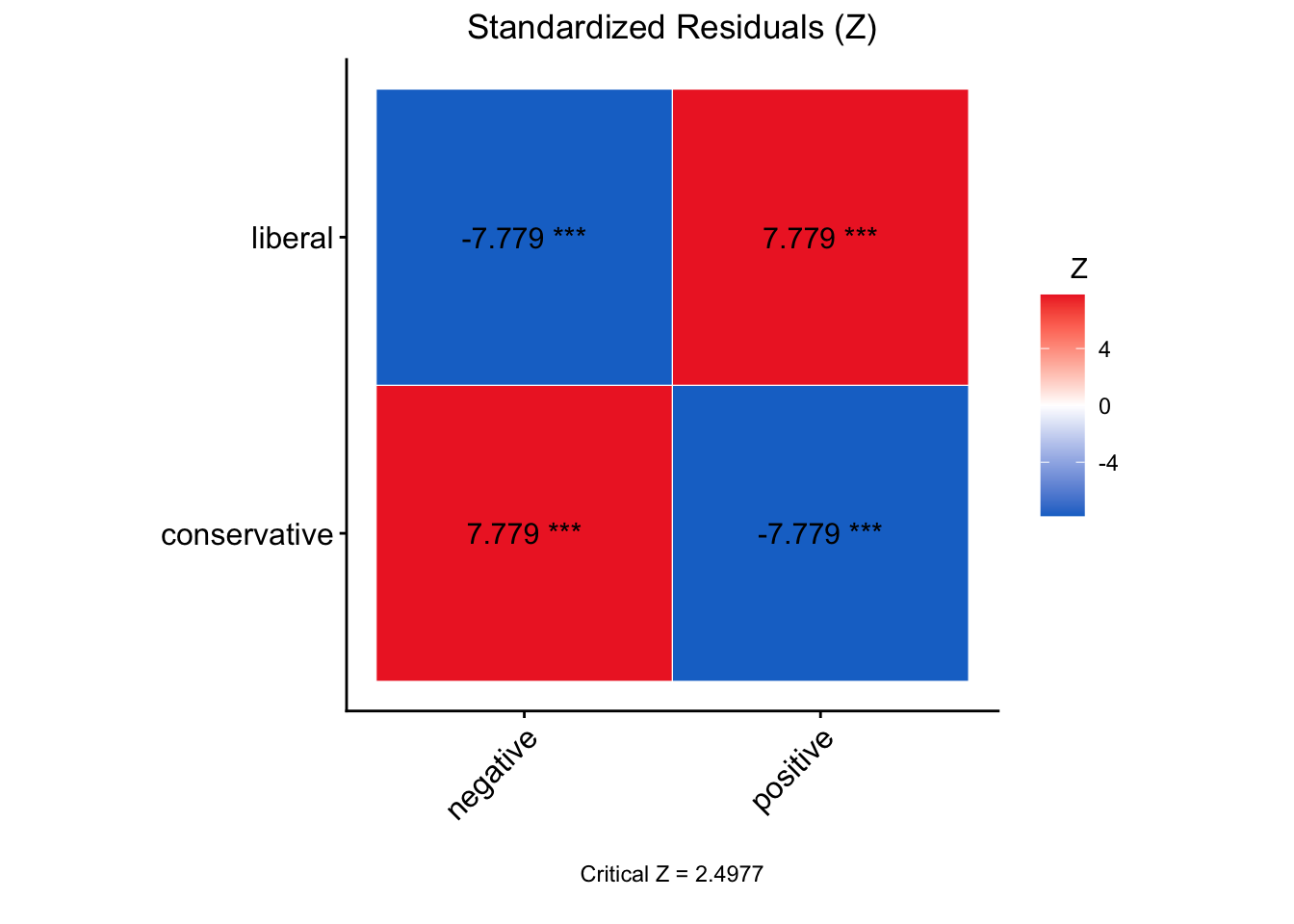
## Call:
## chi.sq(df = data, var1 = views, var2 = pol, post = T, plot = T)
##
## Pearson's Chi-squared test:
##
## χ² Critical χ² df p-value
## 60.506 3.841 1 7.334e-15 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
##
## Post-Hoc Test w/ Bonferroni Adjustment:
## Comparing: pol-views
##
## Standardized Residual (Z) p-value
## conservative-negative 7.7786 2.934e-14 ***
## conservative-positive -7.7786 2.934e-14 ***
## liberal-negative -7.7786 2.934e-14 ***
## liberal-positive 7.7786 2.934e-14 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1In the output above, we see the \(X^2\)-obtained value (60.506), the degrees of freedom (1), and the p-value (7.334e-15 = 7.334 x \(10^{-15}\) = .000000000000007334, which is much less than our set alpha level of .05).
To interpret the findings, we report the following information:
- The test used
- If you reject or fail to reject the null hypothesis
- The variables used in the analysis
- The degrees of freedom, calculated value of the test (\(X^2_{obtained}\)), and \(p-value\)
- \(X^2(df) = X^2_{obtained}\), \(p-value\)
“Using the Chi Square test of independence (\(X^2\)), I reject/fail to reject the null hypothesis that there is no association between variable one and variable 2, in the population, \(X^2(?) = ?, p ? .05\)”
- “Using the Chi Square test of independence (\(X^2\)), I reject the null hypothesis that there is no association between the political orientation and views of the Black Lives Matter movement, in the population, \(X^2(1) = 60.506, p \lt .05\).”